
Il est grand temps de déconstruire un mythe tenace qui freine encore de nombreuses entreprises : non, il n’est pas obligatoire de louer une grappe de Nvidia H100 à 30 000 € l’unité pour exploiter l’IA générative. Avec la maturation fulgurante des modèles open-source (Llama 3, Mistral, Qwen) et la démocratisation des techniques de quantification, l’hébergement local ou sur serveur dédié est devenu une réalité accessible. En tant qu’architecte de solutions IT, je constate chaque jour que le principal frein n’est plus technologique, mais réside dans la méconnaissance du dimensionnement matériel. Cet article vous propose une analyse technique et pragmatique pour comprendre l’architecture GPU/LLM, calculer vos besoins exacts en VRAM, et choisir le matériel adapté à votre cas d’usage réel en 2026.
Les fondamentaux : pourquoi les LLM exigent-ils une architecture GPU ?
Pour comprendre les exigences matérielles de l’intelligence artificielle générative, il faut d’abord saisir la nature mathématique d’un Large Language Model (LLM). Un processeur classique (CPU), bien qu’extrêmement rapide pour exécuter des instructions complexes de manière séquentielle, n’est absolument pas taillé pour l’ingestion massive de données simultanées requise par l’IA.
Au cœur d’un réseau de neurones artificiels se trouve une opération mathématique omniprésente : la multiplication matricielle. Lorsqu’un LLM génère du texte, il calcule les probabilités d’apparition du prochain « token » (fragment de mot) en traversant des milliards de connexions. C’est ici que l’architecture massivement parallèle du GPU (Graphics Processing Unit) prend tout son sens. Là où un CPU haut de gamme possède 24 à 64 cœurs puissants, un GPU comme la RTX 4090 en possède plus de 16 000 (cœurs CUDA), spécifiquement conçus pour traiter des milliers d’opérations mathématiques basiques en même temps.
L’autre concept fondamental à maîtriser est celui des paramètres du modèle. Quand on parle d’un modèle « 8B » ou « 70B » (B pour Billion, milliards en anglais), on fait référence au nombre de poids synaptiques du réseau. Chaque paramètre est une valeur numérique qui doit être chargée dans la mémoire vidéo (VRAM) du GPU pour que le modèle puisse « réfléchir ». Si ces données devaient faire des allers-retours entre le disque dur, la RAM système et le GPU, la latence serait catastrophique (génération de 0.1 token par seconde au lieu de 50).
Le véritable goulot d’étranglement de l’IA générative locale n’est pas la puissance de calcul brute (TFLOPS), mais la bande passante mémoire. Une mémoire très rapide (comme la HBM3 des datacenters ou la GDDR6X) permet d’abreuver les cœurs de calcul à une vitesse suffisante pour garantir une inférence fluide en temps réel.
Enfin, la taille du contexte (Context Window) vient complexifier l’équation. Fournir un document de 10 pages à analyser à un LLM nécessite de garder en mémoire l’historique complet de la conversation. Plus le contexte est grand (jusqu’à 128K ou 1M tokens sur les modèles récents), plus l’empreinte mémoire explose, indépendamment de la taille initiale du modèle.
Méthodologie technique : calculer la VRAM nécessaire pour votre modèle
La VRAM est le nerf de la guerre dans le déploiement d’une IA générative. Une règle d’or que je rappelle souvent à mes clients : si le modèle ne tient pas entièrement dans votre VRAM (et commence à déborder sur la RAM classique du système via le swap), les performances s’effondrent immédiatement. L’estimation précise de cette consommation repose sur trois piliers : les poids du modèle, les activations intermédiaires (le fameux KV Cache), et la taille des lots de requêtes (batch size).
La formule mathématique d’estimation pour l’inférence
Pour dimensionner vos serveurs ou stations de travail, voici la méthodologie de calcul standard que j’utilise lors de mes audits d’infrastructure. Le format par défaut pour l’entraînement d’un modèle est généralement le FP16 (nombre à virgule flottante sur 16 bits). Dans ce format, un seul paramètre pèse exactement 2 octets.
La formule d’estimation de base pour charger le modèle est donc :
VRAM requise = (Nombre de paramètres) × (Taille d’un paramètre) × 1.2
Le coefficient multiplicateur de 1.2 ajoute une indispensable marge de sécurité de 20% pour le système d’exploitation et le contexte de base. Voyons deux exemples concrets en pleine précision (FP16) :
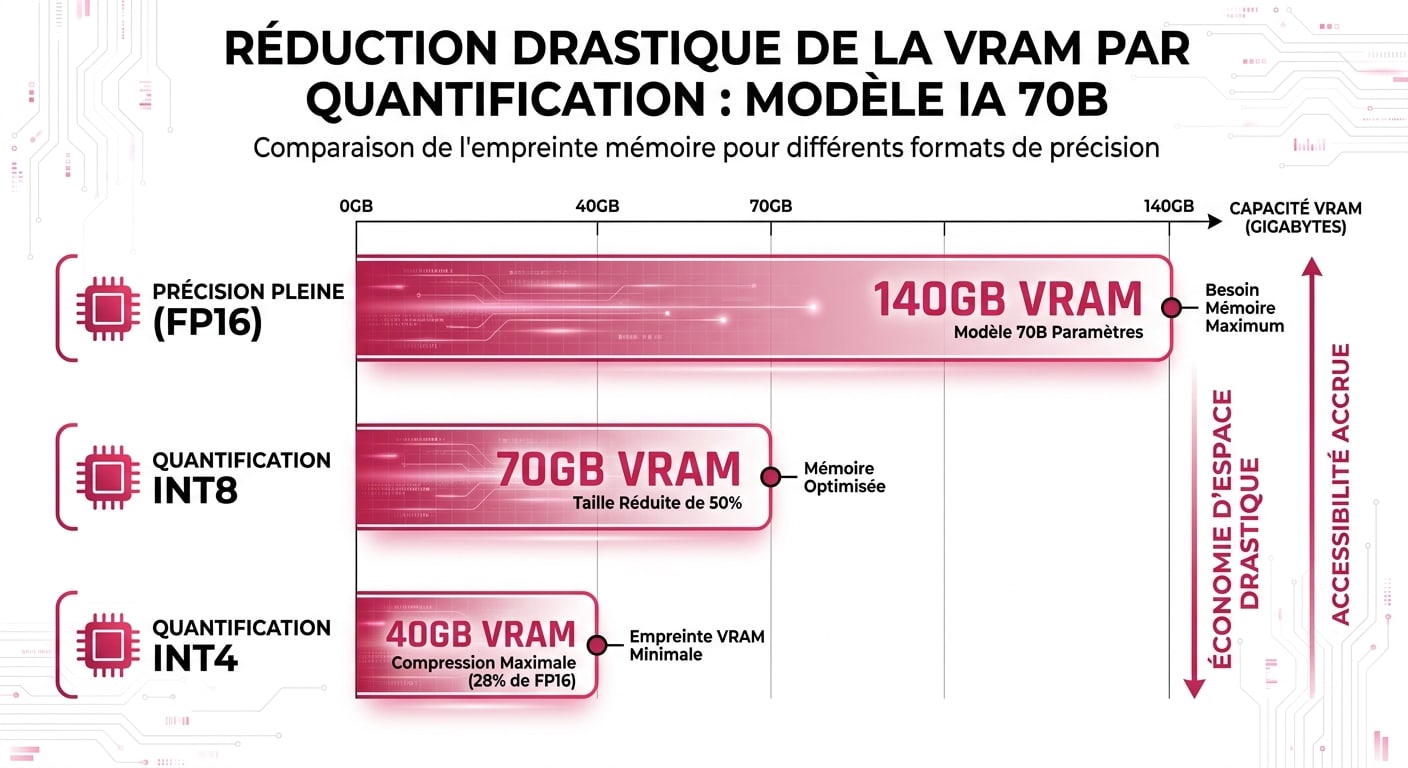
- Pour un modèle 8B (ex: Llama 3 8B) : 8 milliards × 2 octets = 16 Go. Avec la marge de sécurité (1.2), on arrive à environ 19.2 Go de VRAM.
- Pour un modèle 70B : 70 milliards × 2 octets = 140 Go. Avec la marge (1.2), on atteint 168 Go de VRAM.
Tableau comparatif : besoins en VRAM selon la taille du modèle et la quantification
| Taille du Modèle | Pleine Précision (FP16) | Quantification INT8 (8-bit) | Quantification INT4 (4-bit) |
|---|---|---|---|
| 8B (ex: Llama 3) | ~ 19 Go | ~ 10 Go | ~ 6 Go |
| 14B (ex: Qwen 2.5) | ~ 34 Go | ~ 17 Go | ~ 10 Go |
| 32B (ex: Mixtral) | ~ 77 Go | ~ 39 Go | ~ 23 Go |
| 70B (ex: Llama 3) | ~ 168 Go | ~ 84 Go | ~ 48 Go |
L’impact décisif de la taille de contexte (KV Cache)
Si la formule ci-dessus vous permet de démarrer le modèle, elle ne tient pas compte des longues conversations. Le KV Cache (Key-Value Cache) est le mécanisme qui permet au LLM de se souvenir des tokens précédents sans avoir à les recalculer à chaque étape. Ce cache croît de manière linéaire (et parfois exponentielle avec l’attention complète) en fonction du nombre de tokens traités.
Passer d’un contexte de 4K à 128K tokens peut soudainement exiger 10 à 20 Go de VRAM supplémentaires, selon l’architecture du modèle. C’est pour cette raison que des techniques de gestion de la mémoire comme le PagedAttention (démocratisé par le moteur d’inférence vLLM) sont devenues incontournables en production. En allouant la mémoire par petits blocs dynamiques plutôt que par d’immenses segments contigus, PagedAttention permet de traiter jusqu’à 4 fois plus de requêtes simultanées sur un même GPU avec une empreinte VRAM identique.
Optimisation matérielle : faire tourner de gros modèles sur des GPU modestes
Au vu des calculs précédents, déployer un modèle de 70 milliards de paramètres (nécessitant plus de 160 Go de VRAM en natif) semble réservé aux géants de la tech. Pourtant, la communauté open-source a développé des techniques de compression remarquables, rendant l’IA compatible avec des cartes graphiques grand public ou des serveurs de PME. Le principe repose sur un arbitrage minutieux entre précision mathématique et empreinte mémoire.
La quantification : de FP16 à INT4 (GGUF, AWQ, GPTQ)
La quantification est la technique d’optimisation la plus impactante à l’heure actuelle. Elle consiste à réduire la précision numérique des poids du modèle. Au lieu de coder un paramètre sur 16 bits (FP16), on le « compresse » pour qu’il tienne sur 8 bits (INT8), voire 4 bits (INT4). Les chercheurs ont démontré qu’un modèle quantifié en INT4 conserve 95 à 98% de ses capacités de raisonnement initiales, tout en divisant ses besoins en RAM par 4.
Sur le terrain, j’utilise systématiquement trois formats selon l’infrastructure de déploiement :
- GGUF : Le format roi pour l’usage local. Il permet de faire tourner des LLM en répartissant la charge entre le CPU, la RAM système et le GPU. Des outils grand public comme Ollama ou LM Studio s’appuient massivement sur ce format.
- AWQ & GPTQ : Des formats d’inférence purement GPU, optimisés pour un déploiement en production (serveur web, API interne) car ils maximisent la vitesse de génération des tokens (tokens/sec).
Grâce à la quantification INT4, un mastodonte de 70B qui exigeait 168 Go de VRAM peut désormais tourner de manière fluide sur un serveur équipé de « seulement » 48 Go de VRAM, rendant le déploiement interne financièrement viable, en particulier face aux enjeux de souveraineté numérique (un point critique que j’aborde dans mon décryptage de la directive NIS 2).
Le fine-tuning optimisé avec la méthode LoRA
Si l’inférence a été optimisée, l’entraînement d’un modèle l’est tout autant. Le Full Fine-Tuning (l’entraînement complet de tous les paramètres d’un modèle pour l’adapter à vos données d’entreprise) requiert des clusters de dizaines de GPU, car il faut stocker non seulement les poids, mais aussi les gradients et les états de l’optimiseur (multipliant la VRAM par 4 ou 5).
C’est là qu’intervient l’approche LoRA (Low-Rank Adaptation). Cette méthode révolutionnaire consiste à « figer » les milliards de paramètres originaux du LLM, et à n’entraîner qu’un minuscule réseau de neurones additionnel (souvent moins de 1% de la taille totale) qui viendra se greffer sur le modèle principal. Résultat : vous pouvez fine-tuner un modèle 8B avec une simple carte graphique de 24 Go (comme une RTX 3090/4090) en quelques heures, ouvrant la voie à la spécialisation métier à moindre coût.
Méthodologie en 5 étapes : check-list avant de déployer un LLM en local
- Identifier la taille du modèle ciblé : Sélectionnez le modèle adapté à votre besoin (ex: Llama 3 8B pour de la classification, Qwen 32B pour du code).
- Calculer la VRAM requise globale : Prenez en compte les poids ET le KV Cache estimé pour votre taille de contexte maximale.
- Choisir le format de quantification : Optez pour GGUF si vous hybridez CPU/GPU, ou AWQ pour de la performance pure sur GPU dédié.
- Sélectionner le framework d’inférence : Utilisez vLLM pour une API en production à fort trafic, ou Ollama pour du prototypage rapide.
- Monitorer l’utilisation réelle : Une fois lancé, surveillez les pics de charge via la commande terminal
nvidia-smipour ajuster le batch size si nécessaire.
Comparatif matériel 2026 : quel GPU choisir selon votre profil ?

Le marché du hardware est segmenté de manière très claire par Nvidia, qui conserve un monopole de fait sur l’IA générative grâce à son écosystème logiciel CUDA. Choisir le bon matériel demande de dépasser la simple quantité de RAM pour analyser l’architecture sous-jacente (Ada Lovelace, Hopper, et la toute nouvelle génération Blackwell). Comme je l’explique souvent en aidant mes clients à arbitrer leurs investissements IT via une matrice impact effort, il ne sert à rien de surdimensionner l’infrastructure matérielle si le cas d’usage ne le justifie pas.
Pour l’inférence locale et les développeurs (Entrée/Milieu de gamme)
Pour le prototypage, les développeurs indépendants ou l’utilisation d’assistants IA personnels (copilotes de code locaux), la gamme grand public reste pertinente, à une condition : maximiser la VRAM au détriment de la puissance de calcul pur. Dans cette catégorie, la RTX 4060 Ti 16 Go demeure le choix le plus rationnel. Elle offre suffisamment de mémoire pour faire tourner des modèles 8B quantifiés avec un large contexte, le tout pour un tarif contenu et une consommation énergétique faible.
Néanmoins, soyez conscients des limites : la bande passante mémoire (interface 128-bit) est étroite. Votre modèle tiendra en mémoire, mais la vitesse de génération plafonnera souvent autour de 15 à 25 tokens par seconde, ce qui est suffisant pour un usage individuel mais inadapté pour un serveur partagé.
Pour les PME et stations de travail (Haut de gamme / Multi-GPU)
C’est le segment le plus stratégique pour les PME souhaitant internaliser leurs données. Les fleurons de la gamme « Gamer » ou prosumer (RTX 4090 ou les nouvelles séries 5090 équipées de 24 à 32 Go) offrent une bande passante massive et une vitesse d’inférence fulgurante. Cependant, une seule carte atteint vite ses limites face aux modèles de plus de 14B.
Mon conseil d’expert : privilégiez l’approche « Dual GPU » grand public. Coupler deux RTX 4090/3090 d’occasion vous offre 48 Go de VRAM pour une fraction du prix d’une carte professionnelle unique. Cette configuration permet de faire tourner d’excellents modèles 32B (comme Mixtral ou Command-R) quantifiés, avec des temps de réponse dignes d’une API cloud premium.
Pour les datacenters et l’entraînement lourd (Enterprise)
À l’échelle de l’entreprise (déploiement de plateformes internes, fine-tuning massif), le matériel professionnel devient obligatoire, non seulement pour la VRAM (RTX 6000 Ada avec 48 Go, ou les monstres de cloud H100/H200 avec 80 à 141 Go de mémoire HBM3), mais surtout pour des raisons de stabilité et d’interconnexion. La technologie NVLink permet à ces GPU de partager leur mémoire avec une latence quasi-nulle, se comportant comme un seul super-cerveau.
Il faut toutefois noter que l’hébergement de telles infrastructures (une grappe de 8x H100 consommant près de 10 kW) pose de véritables défis thermiques et énergétiques. C’est une dimension que j’ai longuement détaillée dans mon dossier sur l’hébergement vert et la réduction de l’empreinte carbone IT. Face à ce monopole énergétique de Nvidia, on observe l’émergence sérieuse des NPU (Neural Processing Units) et des alternatives comme les puces AMD MI300X, qui commencent enfin à bénéficier d’un support logiciel mature (ROCm) pour casser les prix.
Benchmark 2026 : sélection des meilleurs GPU pour l’IA générative
| Catégorie / Profil | GPU Recommandé | VRAM | Cas d’usage optimal |
|---|---|---|---|
| Rapport Qualité/Prix | Nvidia RTX 4060 Ti 16Go | 16 Go | Inférence personnelle de modèles 7B-9B quantifiés. |
| Workstation Locale | Dual RTX 4090 (ou 5090) | 48 Go (2×24) | Prototypage IA PME, fine-tuning LoRA, inférence de modèles 32B. |
| Serveur Pro Abordable | Nvidia RTX 6000 Ada | 48 Go | Stabilité datacenter, inférence continue sans limitation de licence pilote. |
| Standard Enterprise | Nvidia H100 / H200 | 80+ Go HBM3 | Entraînement complet (Full FT), inférence API massive, parallélisme tensoriel. |
Architecture distribuée : répartir un LLM sur plusieurs GPU
Lorsque vos ambitions (ou la taille du modèle) dépassent la capacité physique de votre plus grande carte graphique, une configuration mono-GPU devient insuffisante. L’orchestration d’un LLM sur plusieurs cartes est un défi d’ingénierie qui nécessite de maîtriser l’architecture distribuée. La stabilité d’un tel système multi-nœuds nécessite d’ailleurs une supervision réseau granulaire, souvent orchestrée via des protocoles éprouvés dont j’ai documenté les bonnes pratiques dans mon guide technique sur le protocole SNMP.
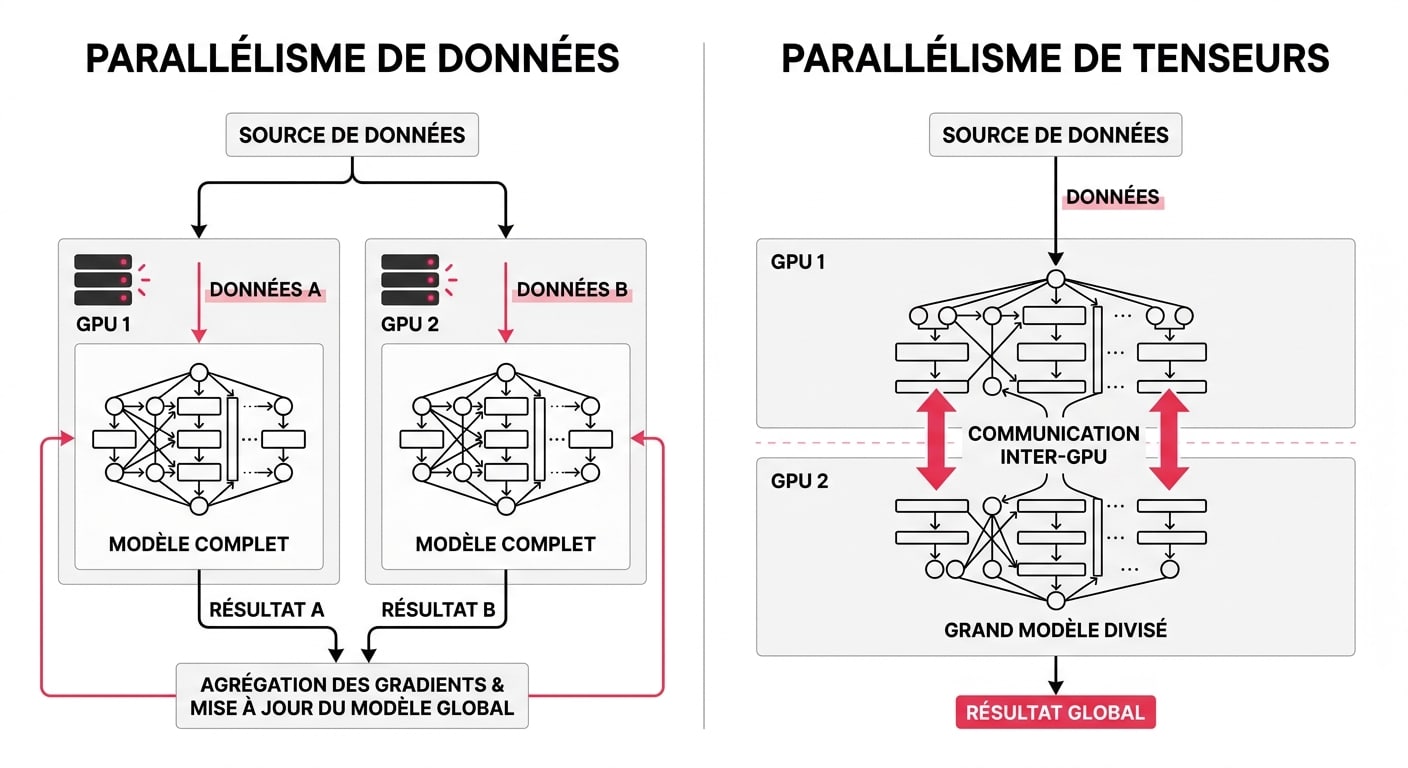
Il existe plusieurs méthodes pour distribuer la charge. Le parallélisme de données (Data Parallelism) est l’approche classique : le modèle est dupliqué à l’identique sur chaque GPU, et on répartit les requêtes des utilisateurs entre eux. C’est parfait pour un service web à très fort trafic (load balancing d’inférence), à condition que chaque GPU ait assez de VRAM pour contenir le modèle entier.
À l’inverse, si le modèle est trop lourd pour une seule carte, on utilise le parallélisme de modèles (Tensor ou Pipeline Parallelism). Ici, on « découpe » littéralement le cerveau de l’IA. Dans le Pipeline Parallelism, les premières couches du réseau de neurones sont calculées sur le GPU 1, qui passe ensuite le résultat au GPU 2 pour les couches suivantes. Dans le Tensor Parallelism (plus complexe mais plus efficace), les opérations mathématiques d’une même couche sont réparties simultanément sur plusieurs GPU.
Le succès de cette distribution repose sur le bus de communication inter-GPU. Dans une station de travail classique, le transfert via les ports PCIe de la carte mère devient un goulot d’étranglement sévère. C’est ici que les ponts NVLink de Nvidia, capables de transférer jusqu’à 900 Go/s entre les cartes, justifient leur prix astronomique dans les datacenters. Pour déployer ces architectures, les ingénieurs s’appuient aujourd’hui sur des frameworks logiciels devenus standards, comme Hugging Face Accelerate, DeepSpeed de Microsoft, ou Ray, qui abstraient la complexité matérielle pour le développeur.



